Иногда необходимо отфильтровать вывод той или иной утилиты, ну или просто найти что‐нибудь в файле или файлах. Для этого есть замечательная утилита grep.
Фильтруем вывод
Для начала, что такое STDOUT, STDERR и STDIN — это виртуальные устройства ввода/вывода расположенные в /dev/stdout, /dev/stderr и /dev/stdin соответственно. В данный момент мы рассмотрим только STDOUT, про остальное я скажу что STDERR — это то же самое, но предназначенное для вывода ошибок, а STDIN — для ввода.
Что же такое stdout? stdout это виртуальное устройство для вывода текстовой (и не только) информации. Работает оно просто, в этот «файл» записывается некая информация, и эта информация выводится системой в консоль. Все программы (консольные) производят вывод информации в /dev/stdout, а система уже выводит эту информацию в консоль, где мы ее и наблюдаем. Поток этой информации можно перенаправлять в другой файл, например, команда echo выводит в stdout то, что ей передали — например echo «hello» выведет в stdout (а система уже выведет это в консоль) слово «hello», но если мы выполним команду echo «hello» > myfile.txt то вывод будет записан в файл myfile.txt, убедиться в этом можно выведя содержимое этого файла с помощью cat myfile.txt. Так же можно перенаправить вывод в stdin другой программы, чтобы эта программа обработала вывод первой программы, ну и вывела его нам как это делет grep. Делается это просто — cat /proc/cpuinfo | wc -l. В этом примере cat /proc/cpuinfo выводит содержимое файла /proc/cpuinfo (в нём находится информация о процессоре), оператор | перенаправляет вывод в stdin команды wc -l, которая посчитает количество строк и выведет нам результат.
Так как же фильтровать вывод? Предположим, что мы хотим посмотреть частоту процессора. Данная информация хранится в /proc/cpuinfo, но там так же хранится масса другой информации которая на не нужна, и cat /proc/cpuinfo выведет на всё, в том числе и то, что нам не нужно. Нам нужно найти шаблон той информации которая нам нужна, шаблоном может быть любое любое слово которое находится на той же строке, на которой находится искомая информация. Например, частота процессора хранится в строке вида:
cpu MHz : 933.000
и шаблоном для этой информации может быть как cpu MHz, так и просто MHz, но не может быть cpu, так как в этом файле есть информация вида:
cpu family : 6 cpu cores : 2
и так далее. Шаблон искомой информации мы нашли, теперь можно попробовать отфильтровать вывод и найти искомую информацию, для этого выполним
cat /proc/cpuinfo | grep "cpu MHz"
и будем наблюдать результат вывода вида:

Хорошо, работает. Но нам стали интересны номера строк где располагается информация. В этом случае нам поможет аргумент -n для команды grep:
cat /proc/cpuinfo | grep -n "cpu MHz"
и в результате мы увидим нечто вроде:
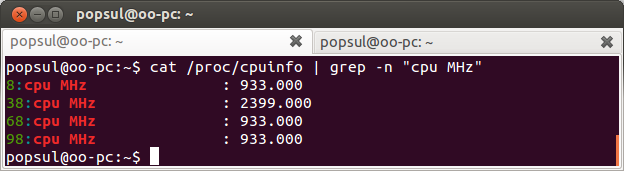
Хорошо, тоже работает. Нам стало лень писать буквы в шаблоне разным регистром, и мы хотим написать просто cpu mhz, или CPU MHZ, для поиска без учёта регистра у grep есть аргумент -i:
cat /proc/cpuinfo | grep -n -i "cpu mhz"
и в результате мы увидим то же самое что и в предыдущем варианте.
Для того чтобы ограничить вывод некоторым количеством строк у grep есть аргумент -m , где N — это количество строк которых нужно вывести:
cat /proc/cpuinfo | grep -n -i -m 2 "cpu mhz"
и в результате у нас будет выведено только две первых строки:
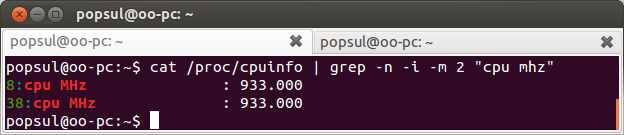
Да, grep после обработки текста выводит результат в stdout, который так же можно обработать grep’ом, или любой другой утилиты, и так до бесконечности:
cat /proc/cpuinfo | grep -n -i -m 2 "cpu mhz" | head -n 1 | tr "c" "g" | tr "M" "G"
И в результате мы получим вывод вида:
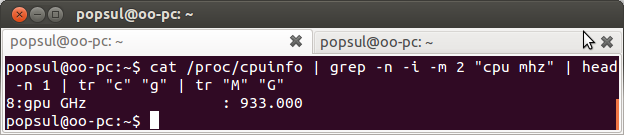
где cat и grep делаю то что и делали выше в примерах, head -n — выводит первых N строк из файла/потока, а tr «c» «g» и tr «M» «G» заменяют первую букву на вторую.
Поиск в файлах
Как и многие утилиты, grep умеет работать с файлами, и производить поиск шаблона в этих файлах. Для примера, мы постараемся получить частоту процессора не используя утилиту cat, для этого нам необходимо выполнить команду:
grep -i -n -m 1 "cpu mhz" /proc/cpuinfo
и в результате мы увидим знакомый результат:

Мы хотим узнать частоту процессора, помним что она где то в /proc лежит, а где именно — не знаем. Для этого нам помогут аргументы -H и -R. Аргумент -H указывает на то, что необходимо вывести название файла в котором был найден шаблон, а аргумент -R указывает на то, что необходимо обойти все каталоги рекурсивно (то есть то что в /proc и глубже). И того у нас получится команда вида:
grep -H -R -i -n "cpu mhz" /proc
и результат работы вида:
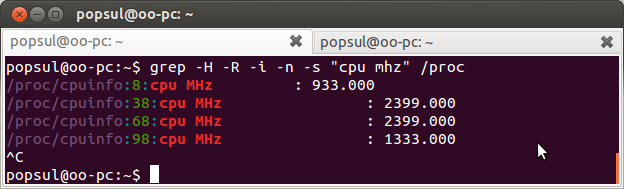
Или же когда мы знаем что информация о процессоре лежит в корне /proc, можно опустить аргумент -R, и изменить путь поиска с /proc, на /proc/*. Если кратко описать, то /proc/* автоматически заменится на список файлов которые находятся в /proc. И в итоге получится команда вида:
grep -H -i -n "cpu mhz" /proc/*
Результат работы будет как на предыдущем примере.
Команда grep умеет так же работать с шаблонами на основе регулярных выражений, но в данной статье мы не будем рассматривать эту возможность.
Более подробное описание всех описанных выше утилит можно почитать в:
- man grep
- man rgrep
- man egrep
- man fgrep
- man cat
- man tr
- man sed
- man head
- man tail
Заключение
Я как и всегда не несу никакой ответственности за вашу систему. Если вы случайно перенаправите вывод какой нибудь программы в файл ядра, или еще в какой нить важный файлик — это исключительно ваши проблемы, а не мои. :)